Intro tentang Sigmoid, Tanh, Softmax, ReLU, dan Leaky ReLU
Activation Function?
Hanya salah satu node yang ditambahkan ke output si Neural Network, atau juga dikenal sebagai Transfer Function. Atau bisa di attach diantara layer si Neural Network.
Kenapa harus menggunakan Activation Function pada NN?
Sebenarnya digunakan untuk menentukan ouput dari si NN seperti yes or no. Fungsi yang memetakan input menjadi 0 sampai 1 atau -1 sampai 1 (tergantung fungsinya).
Pada dasarnya Activation Function dibedakan menjadi 2 tipe:
Linear Activation FunctionNon-linear Activation Function
Linear atau Identity Activation Function
Terlihat bahwa functionnya berbentuk line atau linear. Sehingga, output dari si function tidak terbentuk menjadi sebuah range.
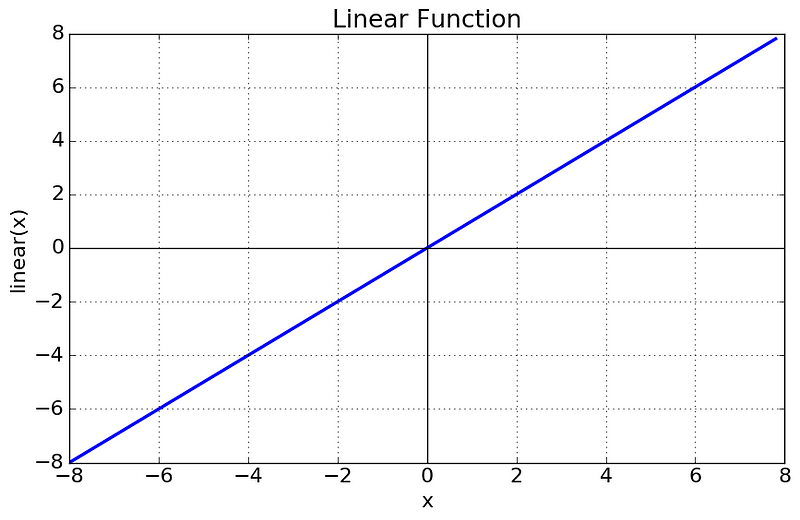
- Persamaan : f(x) = x
- Range : (-tak hingga ke tak hingga)
Ga banyak membantu untuk parameter yang complex.
Non-linear Activation Function
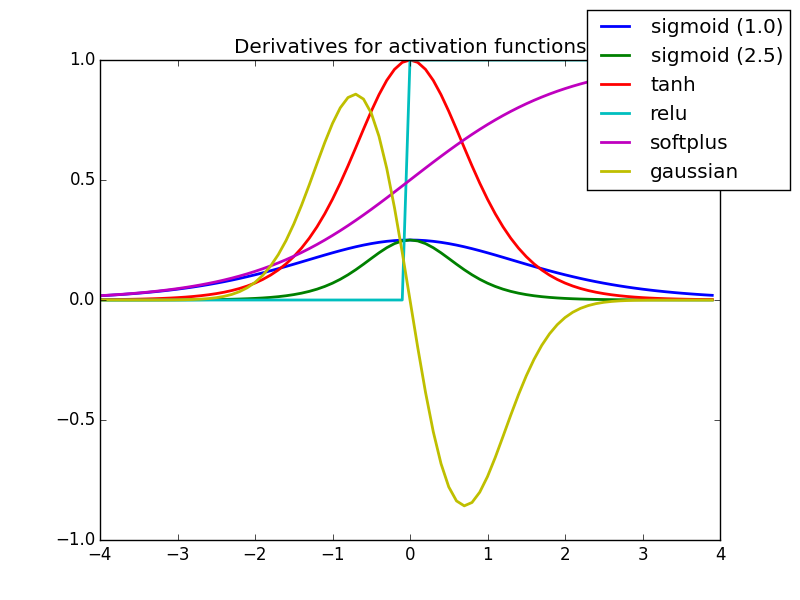
Function yang paling sering digunakan. Nonlinearity akan terlihat seperti ini
Dengan non linear lebih mudah bagi si model untuk beradaptasi dengan data yang vary. Hal yang perlu untuk dipahami pada nonlinear function adalah:
- Derivative atau Differential: Berubah pada y-axis, dan berubah juga pada x-axis nya.I Seperti sebuah slope.
- Monotonic function: Sebuah function yang secara keseluruhan ga menaik atau ga menurun.
Nonlinear Activation Functions secara umum dibagi berdasarkan basis dari rangenya atau curvanya.
Sigmoid atau Logistic Activation Function
Sigmoid Function terlihat seperti S-shape.
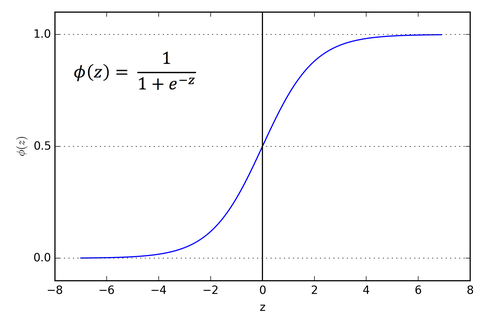
Alasan utama kenapa menggunakan function sigmoid adalah karena nilainya ada di range (0 sampai 1). Sehingga, bisa digunakan oleh model untuk memprediksi probability sebagai output. Karena probability juga nilainya ada di range (0 sampai 1).
- Sigmoid termasuk function yang terdifferensiasi. Yang artinya, kita bisa mendapatkan slope dari kurva simoid dari dua titik sembarang.
- Sigmoid juga termasuk monotonic tapi turunannya enggak.
- Sigmoid logistik dapat mengakibatkan si NN stuck saat waktu training.
- Sigmoid lebih generalisasi logistik sehingga bisa digunakan untuk multiclass classification.
Tanh atau hyperbolic tangent Activation Function
Tanh juga seperti logistic sigmoid tapi lebih bagus. Range dari tanh function berasal dari (-1 sampai 1). Tanh juga berbentuk sigmoidal (s).
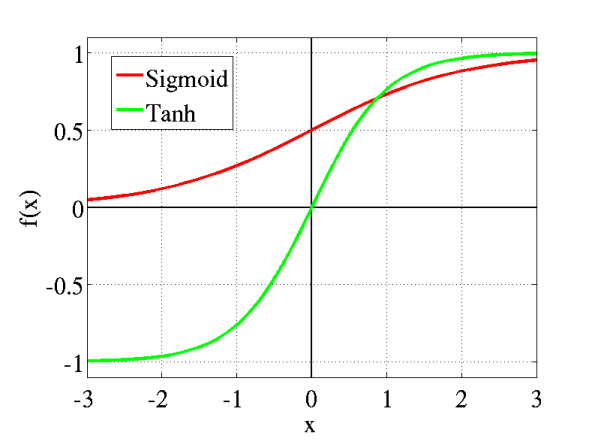
The advantage is that the negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero in the tanh graph.
- Keuntungannya adalah input yang negative akan di mapping ke negative dan input nl akan dimapping ke dekat dengan nol pada tanh.
- Function-nya terdifferensiasi.
- Function-nya monotonix walaupun derivativenya tidak monotonic.
- Tanh Function paling sering digunakan untuk classifikasi diantara dua class.
Tanh dan logistic sigmoid keduanya dalah activation function yang digunakan pada feed-forward.
ReLU (Rectified Linear Unit) Activation Function
ReLU merupakan function yang paling digunakan sampai sekarang, ini digunakan di hampir semua convex atau deep learning lainnya.
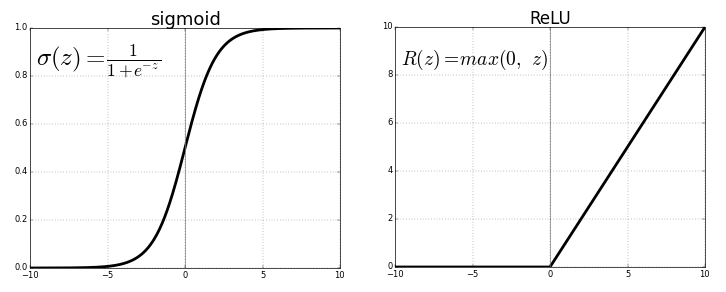
f(z) bernilai nol ketika z kurang dari nol atau sama dengan nol, dan f(z) sama dengan z adalah ketika z lebih dari atau sama dengan nol.
Range: [ 0 sampai takhingga)
- Function dan derivativenya keduanya adalah monotonic.
Tapi masalahnya adalah semua nilai negatif menjadi nol hal tersebut yang menurunkan kemampuan model untuk menyesuaikan atau melatih dari data dengan benar. Itu berarti setiap masukan negatif yang diberikan kepada fungsi aktivasi ReLU mengubah nilai menjadi nol dalam grafik, yang pada gilirannya mempengaruhi grafik yang dihasilkan dengan tidak memetakan nilai negatif secara tepat.
Leaky ReLU
Nah si Leaky datang untuk menyelesaikan masalah di ReLU
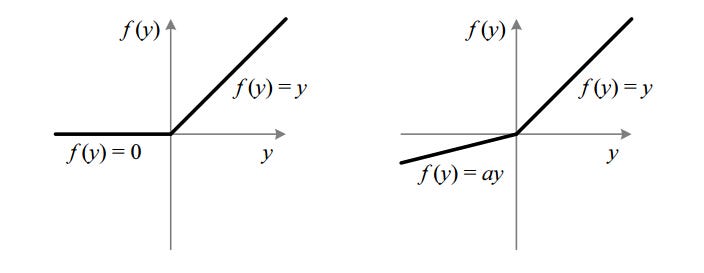
Leaky membantu untuk menambah range dari ReLU. Biasanya nilai dari
aadalah 0.01.- Ketika
atidak bernilai 0.01 maka kita menamakannya sebagai Randomized ReLU. - Range: (-takhingga sampai takhingga)
Leaky dan Randomized ReLU keduanya adalah monotonic. Jadi derivative keduanya juga monotonic.
- Ketika
Lalu kenapa kita menggunakan derivativenya?
Ketika mengupdate kurva, untuk mengetahui ke arah mana dan berapa banyak untuk mengubah atau memperbarui kurva tergantung pada slope. Pada prose forward kita akan menggunakan si function tersebut dan sebaliknya ketika proses backward, derivativenya yang dibutuhkan.
Cheatsheet Activation Function