Salah satu masalah paling umum yang gue sering hadapi dalam Data Cleaning / Exploratory Analysis adalah mising value. Pertama, pahami bahwa TIDAK ada cara yang cukup bagus untuk menangani missing value. Gue udah menemukan solusi yang berbeda untuk imputasi data tergantung pada jenis masalahnya: Time series, ML, Regresi, dll. Dan sulit untuk diselesaikan secara general. Dalam blog ini, gue coba meringkas metode yang paling umum digunakan dan mencoba mencari solusi yang struktural.
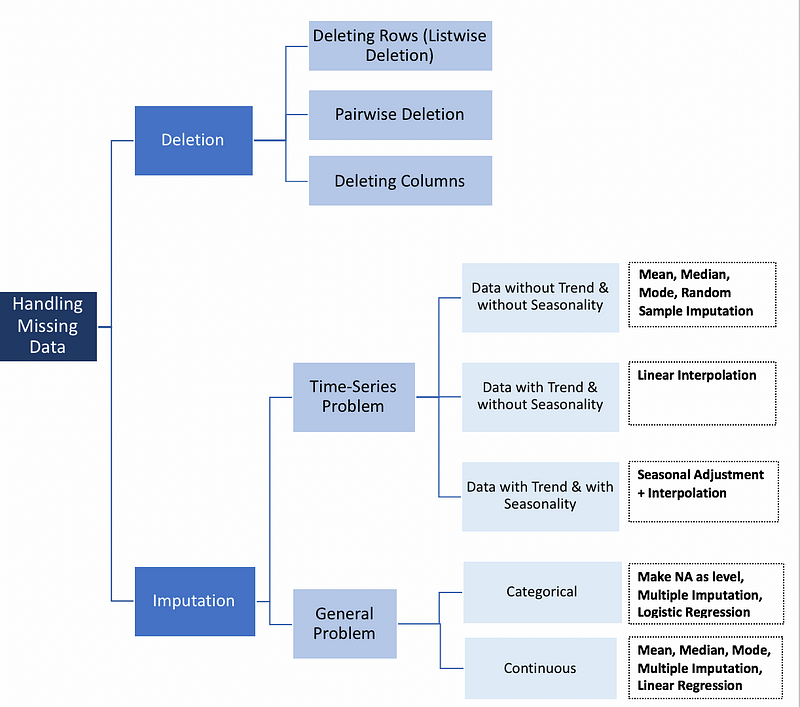
Imputasi atau Delete Data
Sebelum ke metode imputasi, kita harus memahami alasan mengapa data bisa missing.
- Missing at Random (MAR): Missing secara random berarti bahwa kecenderungan untuk sebuah data point yang missing terkait dengan masalah saat observasinya, bukan terkait dengan datanya.
- Missing Completly at Random (MCAR): Sebuah data point tertentu yang missing tidak ada hubungannya dengan hipotetis value atau data point pada variable yang berbeda.
- Missing not a Random (MNAR): Dua alasan yang mungkin bahwa nilai yang missing tergantung pada hipotetis value (misalnya Orang dengan gaji tinggi umumnya tidak ingin mengungkapkan pendapatan mereka dalam sebuah survey) atau nilai yang missing tergantung pada beberapa nilai variabel lain (misalnya asumsi bahwa wanita umumnya tidak ingin mengungkapkan usia mereka, semakin tua dan belum menikah. Di sini, nilai yang missing dalam variabel usia dan pernikahan dipengaruhi oleh variabel jenis kelamin).
Dalam dua kasus pertama, aman kok menghapus data dengan nilai-nilai yang missing tergantung pada kemunculannya, sementara pada kasus ketiga menghapus pengamatan dengan nilai yang missing dapat menghasilkan bias dalam model. Jadi kita harus berhati-hati sebelum delete data observasi. Perhatikan bahwa imputasi tidak selalu memberikan hasil yang lebih baik.
Listwise
Listwise deletion: menghapus semua data untuk observasi yang memiliki satu atau lebih nilai yang missing. Khususnya jika data yang missing terbatas cukup kecil pada data observasi, kita bisa pilih untuk menghilangkan kasus-kasus tersebut dari analisis. Namun dalam banyak kasus, seringkali tidak menguntungkan untuk menggunakan listwise. Hal ini karena asumsi MCAR biasanya jarang didukung. Akibatnya, metode listwise menghasilkan parameter dan perkiraan yang bias.
Pairwise
Pairwise deletion: menganalisa semua kasus di mana variabel of interest ada disitu dengan demikian memaksimalkan semua data yang tersedia berdasarkan analisis. Kelebihan teknik ini, meningkatkan kekuatan dalam analisis tetapi memiliki banyak kerugian. Ini mengasumsikan bahwa data yang missing adalah MCAR. Jika kita menghapus secara pairwise maka kita akan menghasilkan sejumlah pengamatan berbeda yang berkontribusi pada berbagai bagian pada model nantinya, yang dapat membuat interpretasi menjadi susah.
Drop Variabel
Menurut gue, selalu lebih baik menyimpan data daripada membuangnya. Kadang-kadang kita boleh drop variabel, tetapi hanya jika variabel itu tidak signifikan. Karena itu, imputasi selalu menjadi pilihan yang lebih disukai daripada drop variabel.
Metode Time-Series
- Last Observation Carried Forward (LOCF) & Next Observation Carried Backward (NOCB) Ini adalah pendekatan statistik umum untuk analisis data longitudinal yang berulang di mana beberapa pengamatan tindak lanjut mungkin hilang. Data longitudinal melacak sampel yang sama pada titik waktu yang berbeda. Kedua metode ini dapat memperkenalkan bias dalam analisis dan berkinerja buruk ketika data memiliki tren yang terlihat.
- Interpolasi Linear Metode ini bagus untuk time series dengan beberapa tren tetapi tidak cocok untuk data musiman (seasonal)
- Seasonal + Linear Interpolation Metode ini berfungsi baik untuk data dengan tren dan musim
Mean, Median dan Modus
Menghitung mean, median atau modus adalah metode imputasi yang paling sederhana, karena fungsi yang diuji tidak mengambil keuntungan dari karakteristik time series atau hubungan antar variabel. Cepat sih, tapi memiliki kelemahan yang jelas. Salah satu kelemahannya adalah imputasi berarti mengurangi varians dalam dataset.
Code versi R:
library(imputeTS)
na.mean(mydata, option = "mean") # Mean Imputation
na.mean(mydata, option = "median") # Median Imputation
na.mean(mydata, option = "mode") # Mode Imputation
Code versi Python
from sklearn.preprocessing import Imputer
values = mydata.values
imputer = Imputer(missing_values=’NaN’, strategy=’mean’)
transformed_values = imputer.fit_transform(values)
# strategy can be changed to "median" and “most_frequent”
Regresi linier
Beberapa variabel prediktor dengan nilai yang missing diidentifikasi menggunakan matriks korelasi. Prediktor terbaik dipilih dan digunakan sebagai variabel independen dalam persamaan regresi. Variabel dengan data yang missing digunakan sebagai variabel dependen. Kasus dengan data lengkap untuk variabel prediktor digunakan untuk menghasilkan persamaan regresi. Persamaan ini kemudian digunakan untuk memprediksi nilai yang hilang untuk kasus yang tidak lengkap. Dalam proses iteratif, nilai-nilai untuk variabel yang missing dimasukkan dan kemudian digunakan untuk memprediksi variabel dependen. Langkah-langkah ini diulang sampai ada sedikit perbedaan antara nilai prediksi dari satu langkah ke langkah berikutnya.
“Secara teoritis” memberikan perkiraan nilai-nilai yang missing. Namun, ada beberapa kelemahan dari model ini yang cenderung melebihi kelebihannya. Pertama, karena nilai-nilai yang diganti diprediksi dari variabel lain, mereka cenderung fit “too well” dan standard errornya jadi kadaluwarsa. Kita juga harus berasumsi bahwa ada hubungan linear antara variabel yang digunakan dalam persamaan regresi.
Multiple Imputation
- Imputation: Impute missing value dari set data yang tidak lengkap m kali (misal m = 3 pada gambar). Perhatikan bahwa nilai yang diperhitungkan diambil dari suatu distribusi. Simulasi penarikan secara random tidak termasuk ketidakpastian dalam parameter model. Pendekatan yang disarankan menggunakan simulasi Markov Chain Monte Carlo (MCMC). Langkah ini menghasilkan m set data yang lengkap.
- Analysis: Analisis masing-masing data set yang telah selesai.
- Pooling: Padukan hasil analisis m menjadi hasil akhir
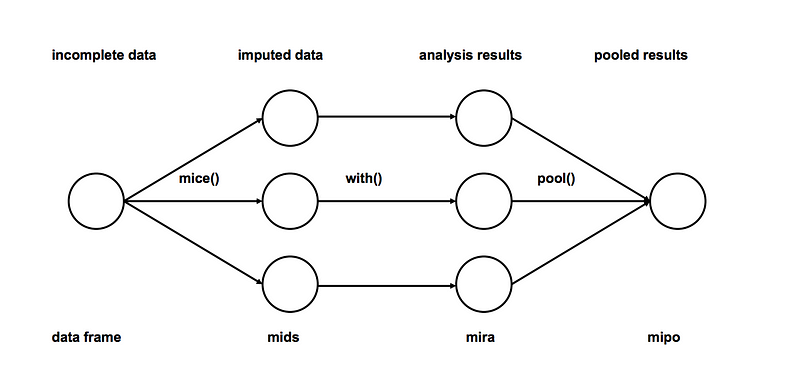
# We will be using mice library in r
library(mice)
# Deterministic regression imputation via mice
imp <- mice(mydata, method = "norm.predict", m = 1)
# Store data
data_imp <- complete(imp)
# Multiple Imputation
imp <- mice(mydata, m = 5)
#build predictive model
fit <- with(data = imp, lm(y ~ x + z))
#combine results of all 5 models
combine <- pool(fit)
Sejauh ini metode imputasi yang digunakan mengandung beberapa alasan diantaranya:
- Mudah digunakan
- Hasil dari impute ga bias
Imputation untuk Categorical Variables
- Imputation menggunakan modus adalah salah satu metode tapi secara jelas akan menjadikan bias
- Nilai yang missing dapat diperlakukan sebagai kategori terpisah dengan sendirinya. Kita bisa membuat kategori lain untuk nilai-nilai yang hilang dan menggunakannya sebagai tingkat yang berbeda. Ini adalah metode yang paling sederhana.
- Model prediksi: Di sini, kita bisa membuat model prediktif untuk memperkirakan nilai yang akan menggantikan data yang missing. Dalam hal ini, kita membagi kumpulan data menjadi dua set: Satu set tanpa nilai yang hilang untuk variabel (training) dan yang lain dengan nilai yang hilang (testing). Kita dapat menggunakan metode seperti regresi logistik dan ANOVA.
- Multiple Imputation
KNN (K Nearest Neighbors)
Ada model machine learning lain seperti XGBoost dan Random Forest untuk imputasi data tapi kita akan membahas KNN karena banyak digunakan. Dalam metode ini, Neighbor k dipilih berdasarkan beberapa ukuran jarak dan rata-rata mereka yang digunakan sebagai perkiraan imputasi. Metode ini membutuhkan pemilihan jumlah Neighbor terdekat, dan jarak sebagai metricnya. KNN dapat memprediksi kedua atribut diskrit (nilai yang paling sering di antara k tetangga terdekat) dan atribut kontinyu (rata-rata di antara k tetangga terdekat).
Metrik jarak bervariasi menurut jenis datanya :
- Data Continuous: Metrik jarak yang umum digunakan untuk data kontinyu adalah Euclidean, Manhattan, dan Cosine
- Data Kategorikal: Jarak Hamming umumnya digunakan dalam kasus ini. Dibutuhkan semua atribut kategori pada setiap datapointnya, hitung satu jika nilainya tidak sama antara dua titik. Jarak Hamming kemudian sama dengan jumlah atribut yang nilainya berbeda.
Salah satu fitur yang paling menarik dari algoritma KNN adalah mudah dimengerti dan mudah diimplementasikan. Sifat non-parametrik KNN memberikannya keunggulan dalam pengaturan tertentu di mana data mungkin sangat “tidak biasa”.
Salah satu kelemahan yang jelas dari algoritma KNN adalah makan waktu ketika menganalisis dataset besar karena mencari contoh serupa melalui seluruh dataset. Selain itu, akurasi KNN dapat sangat terdegradasi dengan data berdimensi tinggi karena ada sedikit perbedaan antara tetangga terdekat dan terjauh.
library(DMwR)
knnOutput <- knnImputation(mydata)
In python
from fancyimpute import KNN
# Use 5 nearest rows which have a feature to fill in each row's missing features
knnOutput = KNN(k=5).complete(mydata)
Di antara semua metode yang dibahas di atas, multiple imputasi dan KNN paling banyak digunakan, dan beberapa imputasi yang lebih sederhana umumnya lebih disukai.